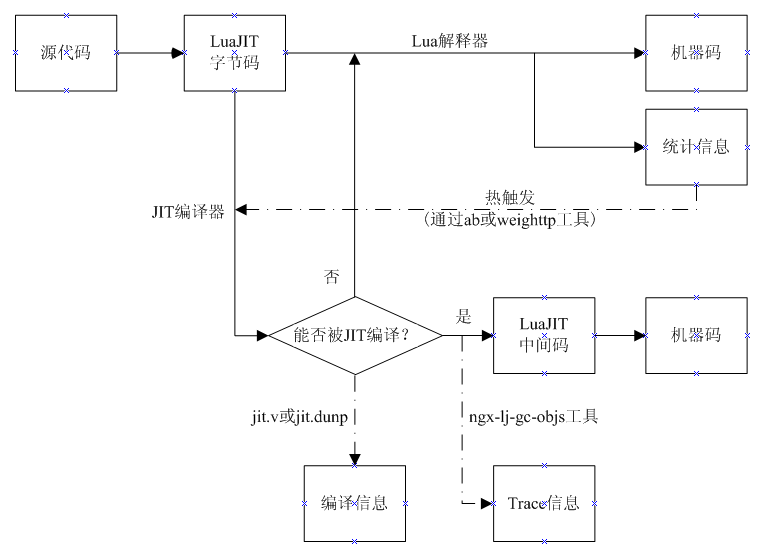
天天看春哥吆喝 代码被 JIT 编译 ,速度提高多少倍,但我一直没弄明白如何去做,才能做到 代码被 JIT 编译。 /path/to/luajit/bin/luajit -b /path/to/input_file.lua /path/to/output_file.luac,这个春哥说不对,只是生成 LuaJIT 字节码,运行时仍然可能被 LuaJIT 解释执行。
Hello! 2013/12/14 lhmwzy: > 天天看春哥吆喝 代码被 JIT 编译 ,速度提高多少倍,但我一直没弄明白如何去做,才能做到 代码被 JIT 编译。 > /path/to/luajit/bin/luajit -b /path/to/input_file.lua > /path/to/output_file.luac,这个春哥说不对,只是生成 LuaJIT 字节码,运行时仍然可能被 LuaJIT > 解释执行。 > LuaJIT 的运行时环境包括一个用手写汇编实现的 Lua 解释器和一个可以直接生成机器代码的 JIT 编译器。 Lua 代码在被执行之前总是会先被lfn 成 LuaJIT 自己定义的字节码(Byte Code)。关于 LuaJIT 字节码的文档,可以参见:http://wiki.luajit.org/Bytecode-2.0(这个文档描述的是; LuaJIT 2.0 的字节码,不过 2.1 里面的变化并不算太大) 一开始的时候,Lua 字节码总是被 LuaJIT 的解释器解释执行。LuaJIT 的解释器会在执行字节码时同时记录一些运行时的统计信息,比如每个 Lua 函数调用入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个预设的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够的“热”,这时便会触发 JIT 编译器开始工作。 JIT 编译器会从热函数的入口或者热循环的某个位置开始尝试编译对应的 Lua 代码路径。编译的过程是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码(比如 x86_64 指令组成的机器码)。 如果当前 Lua 代码路径上的所有的操作都可以被 JIT 编译器顺利编译,则这条编译过的代码路径便被称为一个“trace”,在物理上对应一个 trace 类型的 GC 对象(即参与 Lua GC 的对象)。 你可以通过 ngx-lj-gc-objs 工具看到指定的 nginx worker 进程里所有 trace 对象的一些基本的统计信息,见 https://github.com/agentzh/stapxx#ngx-lj-gc-objs 比如下面这一行 ngx-lj-gc-objs 工具的输出 102 trace objects: max=928, avg=337, min=160, sum=34468 (in bytes) 则表明当前进程内的 LuaJIT VM 里一共有 102 个 trace 类型的 GC 对 象,其中最小的 trace 占用 160 个字节,最大的占用 928 个字节,平均大小是 337 字节,而所有 trace 的总大小是 34468 个字节。 LuaJIT 的 JIT 编译器的实现目前还不完整,有一些基本原语它还无法编译,比如 pairs() 函数、unpack() 函数、string.match() 函数、基于 lua_CFunction 实现的 Lua C 模块、FNEW 字节码,等等。所以当 JIT 编译器在当前代码路径上遇到了它不支持的操作,便会立即终止当前的 trace 编译过程(这被称为 trace abort),而重新退回到解释器模式。 JIT 编译器不支持的原语被称为 NYI(Not Yet Implemented)原语。比较完整的 NYI 列表在这篇文档里面: http://wiki.luajit.org/NYI 所谓“让更多的 Lua 代码被 JIT 编译”,其实就是帮助更多的 Lua 代码路径能为 JIT 编译器所接受。这一般通过两种途径来实现: 1. 调整对应的 Lua 代码,避免使用 NYI 原语。 2. 增强 JIT 编译器,让越来越多的 NYI 原语能够被编译。 对于第 2 种方式,我一直在推动我们公司(CloudFlare)赞助 Mike Pall 的开发工作。不过有些原语因为本身的代价过高,而永远不会被编译,比如基于经典的 lua_CFunction 方式实现的 Lua C 模块(所以需要尽量通过 LuaJIT 的 FFI 来调用 C)。 而对于第 1 种方法,我们如何才能知道具体是哪一行 Lua 代码上的哪一个 NYI 原语终止了 trace 编译呢?答案很简单。就是使用 LuaJIT 安装自带的 jit.v 和 jit.dump 这两个 Lua 模块。这两个 Lua 模块会打印出 JIT 编译器工作的细节过程。 在 Nginx 的上下文中,我们可以在 nginx.conf 文件中的 http {} 配置块中添加下面这一段: init_by_lua ' local verbose = false if verbose then local dump = require "jit.dump" dump.on(nil, "/tmp/jit.log") else local v = require "jit.v" v.on("/tmp/jit.log") end require "resty.core" '; 那一行 require "resty.core" 倒并不是必需的,放在那里的主要目的是为了尽量避免使用 ngx_lua 模块自己的基于 lua_CFunction 的 Lua API,减少 NYI 原语。 在上面这段 Lua 代码中,当 verbose 变量为 false 时(默认就为 false 哈),我们使用 jit.v 模块打印出比较简略的流水信息到 /tmp/jit.log 文件中;而当 verbose 变量为 true 时,我们则使用 jit.dump 模块打印所有的细节信息,包括每个 trace 内部的字节码、IR 码和最终生成的机器指令。 这里我们主要以 jit.v 模块为例。在启动 nginx 之后,应当使用 ab 和 weighttp 这样的工具对相应的服务接口进行预热,以触发 LuaJIT 的 JIT 编译器开始工作(还记得刚才我们说的“热函数”和“热循环”吗?)。预热过程一般不用太久,跑个二三百个请求足矣。当然,压更多的请求也没关系。完事后,我们就可以检查 /tmp/jit.log 文件里面的输出了。 jit.v 模块的输出里如果有类似下面这种带编号的 TRACE 行,则指示成功编译了的 trace 对象,例如 [TRACE 6 shdict.lua:126 return] 这个 trace 对象编号为 6,对应的 Lua 代码路径是从 shdict.lua 文件的第 126 行开始的。 下面这样的也是成功编译了的 trace: [TRACE 16 (15/1) waf-core.lua:419 -> 15] 这个 trace 编号为 16,是从 waf-core.lua 文件的第 419 行开始的,同时它和编号为 15 的 trace 联接了起来。 而下面这个例子则是被中断的 trace: [TRACE --- waf-core.lua:455 -- NYI: FastFunc pairs at waf-core.lua:458] 上面这一行是说,这个 trace 是从 waf-core.lua 文件的第 455 行开始编译的,但当编译到 waf-core.lua 文件的第 458 行时,遇到了一个 NYI 原语编译不了,即 pairs() 这个内建函数,于是当前的 trace 编译过程被迫终止了。 类似的例子还有下面这些: [TRACE --- exit.lua:27 -- NYI: FastFunc coroutine.yield at waf-core.lua:439] [TRACE --- waf.lua:321 -- NYI: bytecode 51 at raven.lua:107] 上面第二行是因为操作码 51 的 LuaJIT 字节码也是 NYI 原语,编译不了。 那么我们如何知道 51 字节码究竟是啥呢?我们可以用 nginx-devel-utils 项目中的 ljbc.lua 脚本来取得 51 号字节码的名字: $ /usr/local/openresty/luajit/bin/luajit-2.1.0-alpha ljbc.lua 51 opcode 51: FNEW 我们看到原来是用来(动态)创建 Lua 函数的 FNEW 字节码。ljbc.lua 脚本的位置是 https://github.com/agentzh/nginx-devel-utils/blob/master/ljbc.lua 非常简单的一个脚本,就几行 Lua 代码。 这里需要提醒的是,不同版本的 LuaJIT 的字节码可能是不相同的,所以一定要使用和你 nginx 链接的同一个 LuaJIT 来运行这个 ljbc.lua 工具,否则有可能会得到错误的结果。 Regards, -agentzh
Hello! 2013/12/14 lhmwzy: > 天天看春哥吆喝 代码被 JIT 编译 ,速度提高多少倍,但我一直没弄明白如何去做,才能做到 代码被 JIT 编译。 > /path/to/luajit/bin/luajit -b /path/to/input_file.lua > /path/to/output_file.luac,这个春哥说不对,只是生成 LuaJIT 字节码,运行时仍然可能被 LuaJIT > 解释执行。 > LuaJIT 的运行时环境包括一个用手写汇编实现的 Lua 解释器和一个可以直接生成机器代码的 JIT 编译器。 Lua 代码在被执行之前总是会先被lfn 成 LuaJIT 自己定义的字节码(Byte Code)。关于 LuaJIT 字节码的文档,可以参见:http://wiki.luajit.org/Bytecode-2.0(这个文档描述的是 LuaJIT 2.0 的字节码,不过 2.1 里面的变化并不算太大) 一开始的时候,Lua 字节码总是被 LuaJIT 的解释器解释执行。LuaJIT 的解释器会在执行字节码时同时记录一些运行时的统计信息,比如每个 Lua 函数调用入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个预设的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够的“热”,这时便会触发 JIT 编译器开始工作。 JIT 编译器会从热函数的入口或者热循环的某个位置开始尝试编译对应的 Lua 代码路径。编译的过程是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码(比如 x86_64 指令组成的机器码)。 如果当前 Lua 代码路径上的所有的操作都可以被 JIT 编译器顺利编译,则这条编译过的代码路径便被称为一个“trace”,在物理上对应一个 trace 类型的 GC 对象(即参与 Lua GC 的对象)。 你可以通过 ngx-lj-gc-objs 工具看到指定的 nginx worker 进程里所有 trace 对象的一些基本的统计信息,见 https://github.com/agentzh/stapxx#ngx-lj-gc-objs 比如下面这一行 ngx-lj-gc-objs 工具的输出 102 trace objects: max=928, avg=337, min=160, sum=34468 (in bytes) 则表明当前进程内的 LuaJIT VM 里一共有 102 个 trace 类型的 GC 对 象,其中最小的 trace 占用 160 个字节,最大的占用 928 个字节,平均大小是 337 字节,而所有 trace 的总大小是 34468 个字节。 LuaJIT 的 JIT 编译器的实现目前还不完整,有一些基本原语它还无法编译,比如 pairs() 函数、unpack() 函数、string.match() 函数、基于 lua_CFunction 实现的 Lua C 模块、FNEW 字节码,等等。所以当 JIT 编译器在当前代码路径上遇到了它不支持的操作,便会立即终止当前的 trace 编译过程(这被称为 trace abort),而重新退回到解释器模式。 JIT 编译器不支持的原语被称为 NYI(Not Yet Implemented)原语。比较完整的 NYI 列表在这篇文档里面: http://wiki.luajit.org/NYI 所谓“让更多的 Lua 代码被 JIT 编译”,其实就是帮助更多的 Lua 代码路径能为 JIT 编译器所接受。这一般通过两种途径来实现: 1. 调整对应的 Lua 代码,避免使用 NYI 原语。 2. 增强 JIT 编译器,让越来越多的 NYI 原语能够被编译。 对于第 2 种方式,我一直在推动我们公司(CloudFlare)赞助 Mike Pall 的开发工作。不过有些原语因为本身的代价过高,而永远不会被编译,比如基于经典的 lua_CFunction 方式实现的 Lua C 模块(所以需要尽量通过 LuaJIT 的 FFI 来调用 C)。 而对于第 1 种方法,我们如何才能知道具体是哪一行 Lua 代码上的哪一个 NYI 原语终止了 trace 编译呢?答案很简单。就是使用 LuaJIT 安装自带的 jit.v 和 jit.dump 这两个 Lua 模块。这两个 Lua 模块会打印出 JIT 编译器工作的细节过程。 在 Nginx 的上下文中,我们可以在 nginx.conf 文件中的 http {} 配置块中添加下面这一段: init_by_lua ' local verbose = false if verbose then local dump = require "jit.dump" dump.on(nil, "/tmp/jit.log") else local v = require "jit.v" v.on("/tmp/jit.log") end require "resty.core" '; 那一行 require "resty.core" 倒并不是必需的,放在那里的主要目的是为了尽量避免使用 ngx_lua 模块自己的基于 lua_CFunction 的 Lua API,减少 NYI 原语。 在上面这段 Lua 代码中,当 verbose 变量为 false 时(默认就为 false 哈),我们使用 jit.v 模块打印出比较简略的流水信息到 /tmp/jit.log 文件中;而当 verbose 变量为 true 时,我们则使用 jit.dump 模块打印所有的细节信息,包括每个 trace 内部的字节码、IR 码和最终生成的机器指令。 这里我们主要以 jit.v 模块为例。在启动 nginx 之后,应当使用 ab 和 weighttp 这样的工具对相应的服务接口进行预热,以触发 LuaJIT 的 JIT 编译器开始工作(还记得刚才我们说的“热函数”和“热循环”吗?)。预热过程一般不用太久,跑个二三百个请求足矣。当然,压更多的请求也没关系。完事后,我们就可以检查 /tmp/jit.log 文件里面的输出了。 jit.v 模块的输出里如果有类似下面这种带编号的 TRACE 行,则指示成功编译了的 trace 对象,例如 [TRACE 6 shdict.lua:126 return] 这个 trace 对象编号为 6,对应的 Lua 代码路径是从 shdict.lua 文件的第 126 行开始的。 下面这样的也是成功编译了的 trace: [TRACE 16 (15/1) waf-core.lua:419 -> 15] 这个 trace 编号为 16,是从 waf-core.lua 文件的第 419 行开始的,同时它和编号为 15 的 trace 联接了起来。 而下面这个例子则是被中断的 trace: [TRACE --- waf-core.lua:455 -- NYI: FastFunc pairs at waf-core.lua:458] 上面这一行是说,这个 trace 是从 waf-core.lua 文件的第 455 行开始编译的,但当编译到 waf-core.lua 文件的第 458 行时,遇到了一个 NYI 原语编译不了,即 pairs() 这个内建函数,于是当前的 trace 编译过程被迫终止了。 类似的例子还有下面这些: [TRACE --- exit.lua:27 -- NYI: FastFunc coroutine.yield at waf-core.lua:439] [TRACE --- waf.lua:321 -- NYI: bytecode 51 at raven.lua:107] 上面第二行是因为操作码 51 的 LuaJIT 字节码也是 NYI 原语,编译不了。 那么我们如何知道 51 字节码究竟是啥呢?我们可以用 nginx-devel-utils 项目中的 ljbc.lua 脚本来取得 51 号字节码的名字: $ /usr/local/openresty/luajit/bin/luajit-2.1.0-alpha ljbc.lua 51 opcode 51: FNEW 我们看到原来是用来(动态)创建 Lua 函数的 FNEW 字节码。ljbc.lua 脚本的位置是 https://github.com/agentzh/nginx-devel-utils/blob/master/ljbc.lua 非常简单的一个脚本,就几行 Lua 代码。 这里需要提醒的是,不同版本的 LuaJIT 的字节码可能是不相同的,所以一定要使用和你 nginx 链接的同一个 LuaJIT 来运行这个 ljbc.lua 工具,否则有可能会得到错误的结果。 Regards, -agentzh --
Hello! 2013/12/15 aCayF > > 画了张图理解了一下,图在下,有哪里理解不对的还望大家能及时帮我指出,谢谢 这张图里有一个明显的错误是 LuaJIT 解释器并不会把 LuaJIT 字节码转换成机器码,而是直接运行之。这正是“解释”的含义。 Regards, -agentzh
Hello! 2013/12/15 aCayF > > 画了张图理解了一下,图在下,有哪里理解不对的还望大家能及时帮我指出,谢谢 这张图里有一个明显的错误是 LuaJIT 解释器并不会把 LuaJIT 字节码转换成机器码,而是直接运行之。这正是“解释”的含义。 Regards, -agentzh --
Hello! 2013/12/14 lhmwzy: > 天天看春哥吆喝 代码被 JIT 编译 ,速度提高多少倍,但我一直没弄明白如何去做,才能做到 代码被 JIT 编译。 > /path/to/luajit/bin/luajit -b /path/to/input_file.lua > /path/to/output_file.luac,这个春哥说不对,只是生成 LuaJIT 字节码,运行时仍然可能被 LuaJIT > 解释执行。 > LuaJIT 的运行时环境包括一个用手写汇编实现的 Lua 解释器和一个可以直接生成机器代码的 JIT 编译器。 Lua 代码在被执行之前总是会先被lfn 成 LuaJIT 自己定义的字节码(Byte Code)。关于 LuaJIT 字节码的文档,可以参见:http://wiki.luajit.org/Bytecode-2.0(这个文档描述的是 LuaJIT 2.0 的字节码,不过 2.1 里面的变化并不算太大) 一开始的时候,Lua 字节码总是被 LuaJIT 的解释器解释执行。LuaJIT 的解释器会在执行字节码时同时记录一些运行时的统计信息,比如每个 Lua 函数调用入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个预设的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够的“热”,这时便会触发 JIT 编译器开始工作。 JIT 编译器会从热函数的入口或者热循环的某个位置开始尝试编译对应的 Lua 代码路径。编译的过程是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码(比如 x86_64 指令组成的机器码)。 如果当前 Lua 代码路径上的所有的操作都可以被 JIT 编译器顺利编译,则这条编译过的代码路径便被称为一个“trace”,在物理上对应一个 trace 类型的 GC 对象(即参与 Lua GC 的对象)。 你可以通过 ngx-lj-gc-objs 工具看到指定的 nginx worker 进程里所有 trace 对象的一些基本的统计信息,见 https://github.com/agentzh/stapxx#ngx-lj-gc-objs 比如下面这一行 ngx-lj-gc-objs 工具的输出 102 trace objects: max=928, avg=337, min=160, sum=34468 (in bytes) 则表明当前进程内的 LuaJIT VM 里一共有 102 个 trace 类型的 GC 对 象,其中最小的 trace 占用 160 个字节,最大的占用 928 个字节,平均大小是 337 字节,而所有 trace 的总大小是 34468 个字节。 LuaJIT 的 JIT 编译器的实现目前还不完整,有一些基本原语它还无法编译,比如 pairs() 函数、unpack() 函数、string.match() 函数、基于 lua_CFunction 实现的 Lua C 模块、FNEW 字节码,等等。所以当 JIT 编译器在当前代码路径上遇到了它不支持的操作,便会立即终止当前的 trace 编译过程(这被称为 trace abort),而重新退回到解释器模式。 JIT 编译器不支持的原语被称为 NYI(Not Yet Implemented)原语。比较完整的 NYI 列表在这篇文档里面: http://wiki.luajit.org/NYI 所谓“让更多的 Lua 代码被 JIT 编译”,其实就是帮助更多的 Lua 代码路径能为 JIT 编译器所接受。这一般通过两种途径来实现: 1. 调整对应的 Lua 代码,避免使用 NYI 原语。 2. 增强 JIT 编译器,让越来越多的 NYI 原语能够被编译。 对于第 2 种方式,我一直在推动我们公司(CloudFlare)赞助 Mike Pall 的开发工作。不过有些原语因为本身的代价过高,而永远不会被编译,比如基于经典的 lua_CFunction 方式实现的 Lua C 模块(所以需要尽量通过 LuaJIT 的 FFI 来调用 C)。 而对于第 1 种方法,我们如何才能知道具体是哪一行 Lua 代码上的哪一个 NYI 原语终止了 trace 编译呢?答案很简单。就是使用 LuaJIT 安装自带的 jit.v 和 jit.dump 这两个 Lua 模块。这两个 Lua 模块会打印出 JIT 编译器工作的细节过程。 在 Nginx 的上下文中,我们可以在 nginx.conf 文件中的 http {} 配置块中添加下面这一段: init_by_lua ' local verbose = false if verbose then local dump = require "jit.dump" dump.on(nil, "/tmp/jit.log") else local v = require "jit.v" v.on("/tmp/jit.log") end require "resty.core" '; 那一行 require "resty.core" 倒并不是必需的,放在那里的主要目的是为了尽量避免使用 ngx_lua 模块自己的基于 lua_CFunction 的 Lua API,减少 NYI 原语。 在上面这段 Lua 代码中,当 verbose 变量为 false 时(默认就为 false 哈),我们使用 jit.v 模块打印出比较简略的流水信息到 /tmp/jit.log 文件中;而当 verbose 变量为 true 时,我们则使用 jit.dump 模块打印所有的细节信息,包括每个 trace 内部的字节码、IR 码和最终生成的机器指令。 这里我们主要以 jit.v 模块为例。在启动 nginx 之后,应当使用 ab 和 weighttp 这样的工具对相应的服务接口进行预热,以触发 LuaJIT 的 JIT 编译器开始工作(还记得刚才我们说的“热函数”和“热循环”吗?)。预热过程一般不用太久,跑个二三百个请求足矣。当然,压更多的请求也没关系。完事后,我们就可以检查 /tmp/jit.log 文件里面的输出了。 jit.v 模块的输出里如果有类似下面这种带编号的 TRACE 行,则指示成功编译了的 trace 对象,例如 [TRACE 6 shdict.lua:126 return] 这个 trace 对象编号为 6,对应的 Lua 代码路径是从 shdict.lua 文件的第 126 行开始的。 下面这样的也是成功编译了的 trace: [TRACE 16 (15/1) waf-core.lua:419 -> 15] 这个 trace 编号为 16,是从 waf-core.lua 文件的第 419 行开始的,同时它和编号为 15 的 trace 联接了起来。 而下面这个例子则是被中断的 trace: [TRACE --- waf-core.lua:455 -- NYI: FastFunc pairs at waf-core.lua:458] 上面这一行是说,这个 trace 是从 waf-core.lua 文件的第 455 行开始编译的,但当编译到 waf-core.lua 文件的第 458 行时,遇到了一个 NYI 原语编译不了,即 pairs() 这个内建函数,于是当前的 trace 编译过程被迫终止了。 类似的例子还有下面这些: [TRACE --- exit.lua:27 -- NYI: FastFunc coroutine.yield at waf-core.lua:439] [TRACE --- waf.lua:321 -- NYI: bytecode 51 at raven.lua:107] 上面第二行是因为操作码 51 的 LuaJIT 字节码也是 NYI 原语,编译不了。 那么我们如何知道 51 字节码究竟是啥呢?我们可以用 nginx-devel-utils 项目中的 ljbc.lua 脚本来取得 51 号字节码的名字: $ /usr/local/openresty/luajit/bin/luajit-2.1.0-alpha ljbc.lua 51 opcode 51: FNEW 我们看到原来是用来(动态)创建 Lua 函数的 FNEW 字节码。ljbc.lua 脚本的位置是 https://github.com/agentzh/nginx-devel-utils/blob/master/ljbc.lua 非常简单的一个脚本,就几行 Lua 代码。 这里需要提醒的是,不同版本的 LuaJIT 的字节码可能是不相同的,所以一定要使用和你 nginx 链接的同一个 LuaJIT 来运行这个 ljbc.lua 工具,否则有可能会得到错误的结果。 Regards, -agentzh
Hello! 2013/12/15 aCayF: > 哈,谢春哥指正,不过想问一下春哥那lua解释器是生成什么来让具体机器执行的,我把这个填到该修改的方框中去 > “解释器”都不会再自己生成东西的,生成东西就变成“编译器”了。“解释器”就像一个虚拟机,直接运行作为输入的代码。这就好比物理 CPU 会直接执行机器指令而不会再生成什么东西一样。从这个意义上讲,物理 CPU 就相当于一个“解释器”。 这些都是编译理论里面的基本概念了。 Regards, -agentzh
Hello! 2013/12/15 nzzlds: > 代码路径是指整个函数或者do...end块吗? > 我写了个简单的测试代码,发现 print(t()) 里的函数 t > 能被JIT编译,但是如果将print放进函数里,则会因为多加进来的这个NYI而被中断。 > 不是。这里的路径是指 LuaJIT 的解释器实际执行过的(线性的) Lua 字节码序列(对应相应的 Lua 语句序列)。所以即使代码里有一个 if 语句没有实际进入,里面的东西也不会算在这里编译的“路径”内。 考虑下面这个例子: $ luajit -jv -e 'function foo(a) if a < 0 then print(a) end end \ for i = 1, 200 do foo(i) end' [TRACE 1 (command line):1 loop] 我们看到,虽然 foo 函数里使用了不能被 JIT 编译的 print() 函数,但由于在整个执行过程中,调用 print() 的代码路径从未执行过(即 if a < 0 这个条件没满足过),所以也不会影响 JIT 编译。LuaJIT 仍然成功地生成了一个 loop 类型的 trace. 我们已经知道,被编译的一条代码路径(或者说一个 trace)起始于一个“热代码块”调用的入口或者一个“热循环”,那么它又终止于何处呢?一般地,“热代码块”类型的 trace 终止于 1. 它遇到的第一个已经编译好的嵌套 trace,或者 2. 当前代码块的结束位置,包括显式的 return 语句。 而“热循环”类型的 trace 一般当前循环体的结束位置。 LuaJIT 的 JIT 编译器是基于 tracing 的。这不同于 JVM、V8、.Net CLR 这些基于 method 的 JIT 编译器。在基于 method 的 JIT 编译器中,编译的单位是整个函数(或方法),而不是真正意义上的细粒度的代码路径。 > 如果真的是会中断整个函数的编译而回退到字节码执行, 只会中断当前的“代码路径”的编译,而不是整个函数。 > 那么对于一些经常被调用的函数,分拆出一些没有NYI的子函数,这样会改善性能吗? > 不一定。因为频繁进出被编译的代码路径的开销也是很大的。因为离开 JIT 出来的机器码时都需要通过 snapshot 同步 LuaJIT VM 的状态。 只有当 NYI 在你的热代码路径中足够稀疏时才有意义。 按照计划,这个月底 Mike Pall 便会(在 CloudFlare 的赞助下)给 LuaJIT 2.1 的 JIT 编译器实现一个新特性,即自动隔离 NYI 原语,总是编译 NYI 前后的两段热代码(作为两个独立的 trace),届时你也不用自己进行拆分了。当然,这种模式获得性能提升的关键依然是 NYI 足够的稀疏。因为先前说的进出 trace 的开销大的问题依然存在。 Regards, -agentzh
Hello! 2013/12/15 aCayF: > 哈,谢春哥指正,不过想问一下春哥那lua解释器是生成什么来让具体机器执行的,我把这个填到该修改的方框中去 > “解释器”都不会再自己生成东西的,生成东西就变成“编译器”了。“解释器”就像一个虚拟机,直接运行作为输入的代码。这就好比物理 CPU 会直接执行机器指令而不会再生成什么东西一样。从这个意义上讲,物理 CPU 就相当于一个“解释器”。 这些都是编译理论里面的基本概念了。 Regards, -agentzh --
Hello! 2014-03-23 20:22 GMT-07:00 Jian Wu: > LuaJIT为什么不把所有能编译的代码都编译了呢?非要等到接口调用足够热的时候呢? > 因为 LuaJIT 需要采集 Lua 程序在实际运行时的统计信息,结合一系列启发性规则,来指导 JIT 编译的编译和优化策略。一个静止的动态类型语言的脚本程序,其实并没有太多可以优化的地方。 Regards, -agentzh