春兄,邮件中提到的rr是什么工具?在哪里可以找到?
openresty-valgrind 和 openresty-asan 这两个工具在哪里可以找到?
谢谢!
------------------ 原始邮件 ------------------
发件人: "Yichun Zhang (agentzh)"<age...@gmail.com>;
发送时间: 2019年5月18日(星期六) 上午6:47
收件人: "openresty"<openresty@googlegroups.com>;
主题: Re: [openresty] 部分worker cpu 使用率 100%
Hello!
那样的话,你的内存损坏问题很严重了,上面看到的估计都离第一现场很远了。建议你上 valgrind 或 asan 来分析内存是否存在越界读写或释放后继续使用等问题了。记得使用 openresty-valgrind 和 openresty-asan 这两个包。另一个选择是使用 rr 录制全过程,然后从崩溃位置回溯。两种方向。
Yichun
hi,春哥
我随机抽取了一个时间点看了一下,其他 worker 进程的调用栈中没ngx_rwlock_wlock()函数或者其他锁函数。
Linux 系统的 dmesg 输出中可以看出有几个 worker 进程 core 了,由于进程号和出问题的 worker 进程不一样切时间点也不是很 match,还不能确认是否相关
我们没有使用 upstream 中的 zone 指令,这也是我最开始怀疑的地方,从配置文件中看,的确没有使用这个指令。
Hello!
你提供的信息过少,你可以检查一下 *lock 的值,即当前一共有多少个 reader 持有读锁,然后比较一下其他 worker 进程里是否有这么多 reader。
有一种可能是你的 nginx worker 进程可能在持有读锁时崩掉了,从而导致读写锁的状态和实际情况不一致,最终读锁永远没法释放,而写锁会死锁。建议检查你的 nginx worker 是否存在意外崩溃的情况(可以查看 nginx error.log 文件和 Linux 系统的 dmesg 输出)。
另一方面,nginx 的读写锁还是挺蛋疼的,所以建议尽量不要使用,换言之,不要使用 upstream 的 zone 指令,以避免这样的风险。
Yichun
现象: 部分 worker cpu 使用率 100%
进程火焰图:
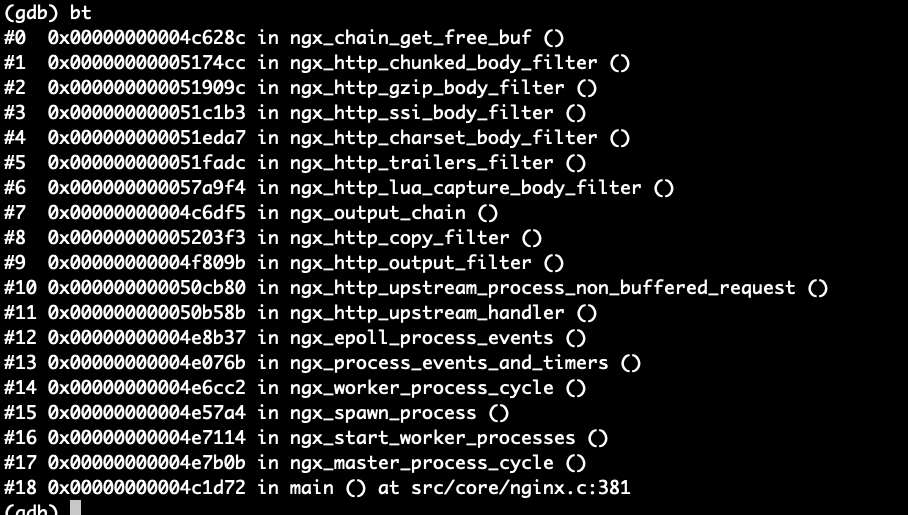
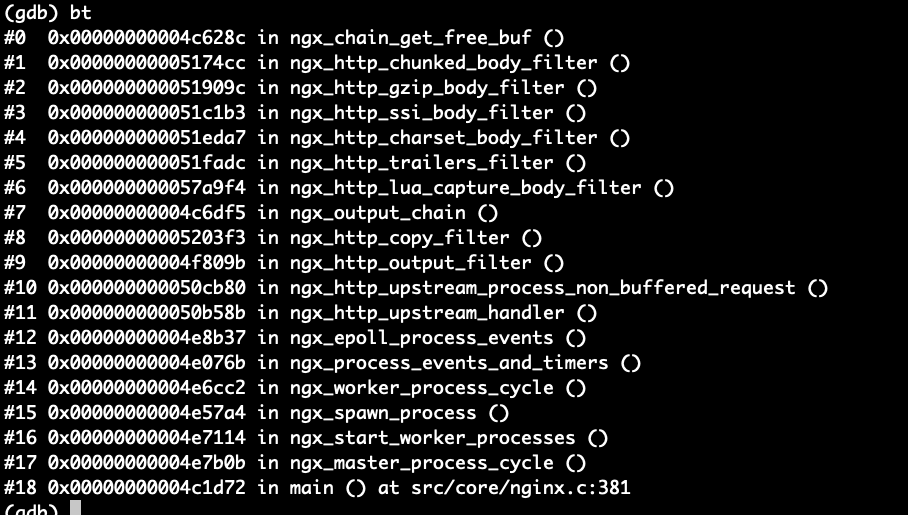
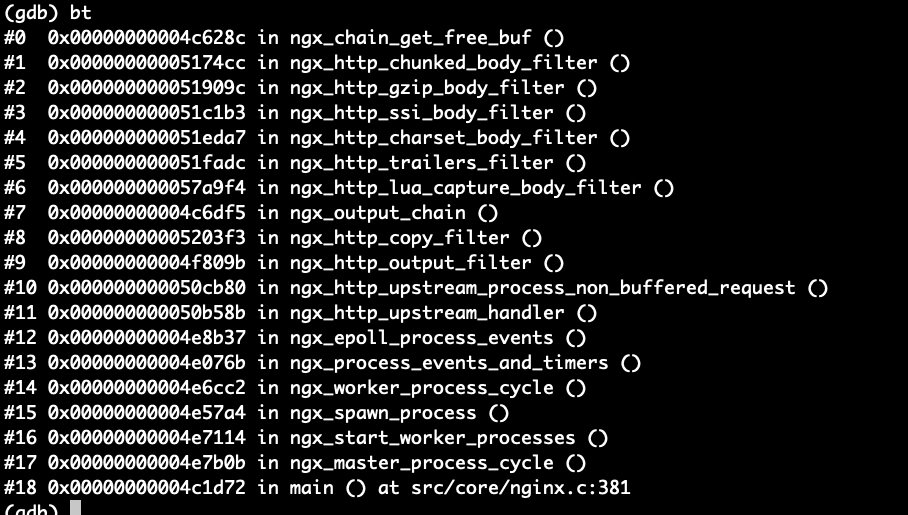
进程堆栈信息:
从上面这些信息来看,貌似是 nginx upstream 在断开 与下游连接时 出问题了,在ngx_rwlock_wlock函数上死锁了。请问各位大神又遇到类似问题的吗?如何解决?
补充:
1. 再 后端(长连接)重启时概率出现这种情况
2. 不能自动恢复,worker 对应进程 打开的 fd 最后修改时间一直是后端重启的时间点