背景后端服务故障,服务重启,nginx 出 core (和后端服务出故障的几个关键时间点吻合,后端打开fd飙升、服务止损重启等)。
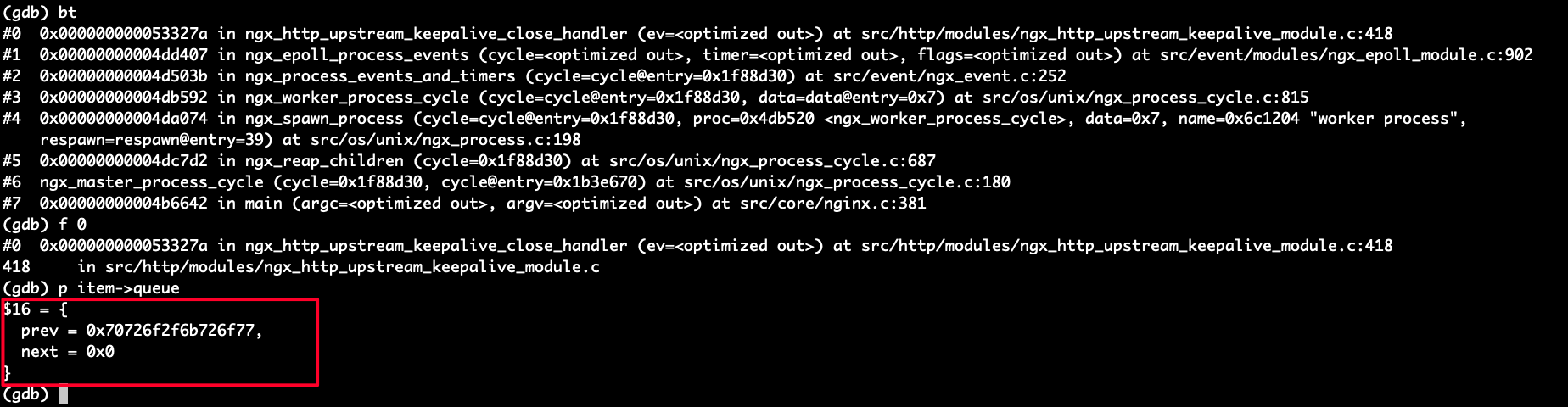
堆栈信息如下
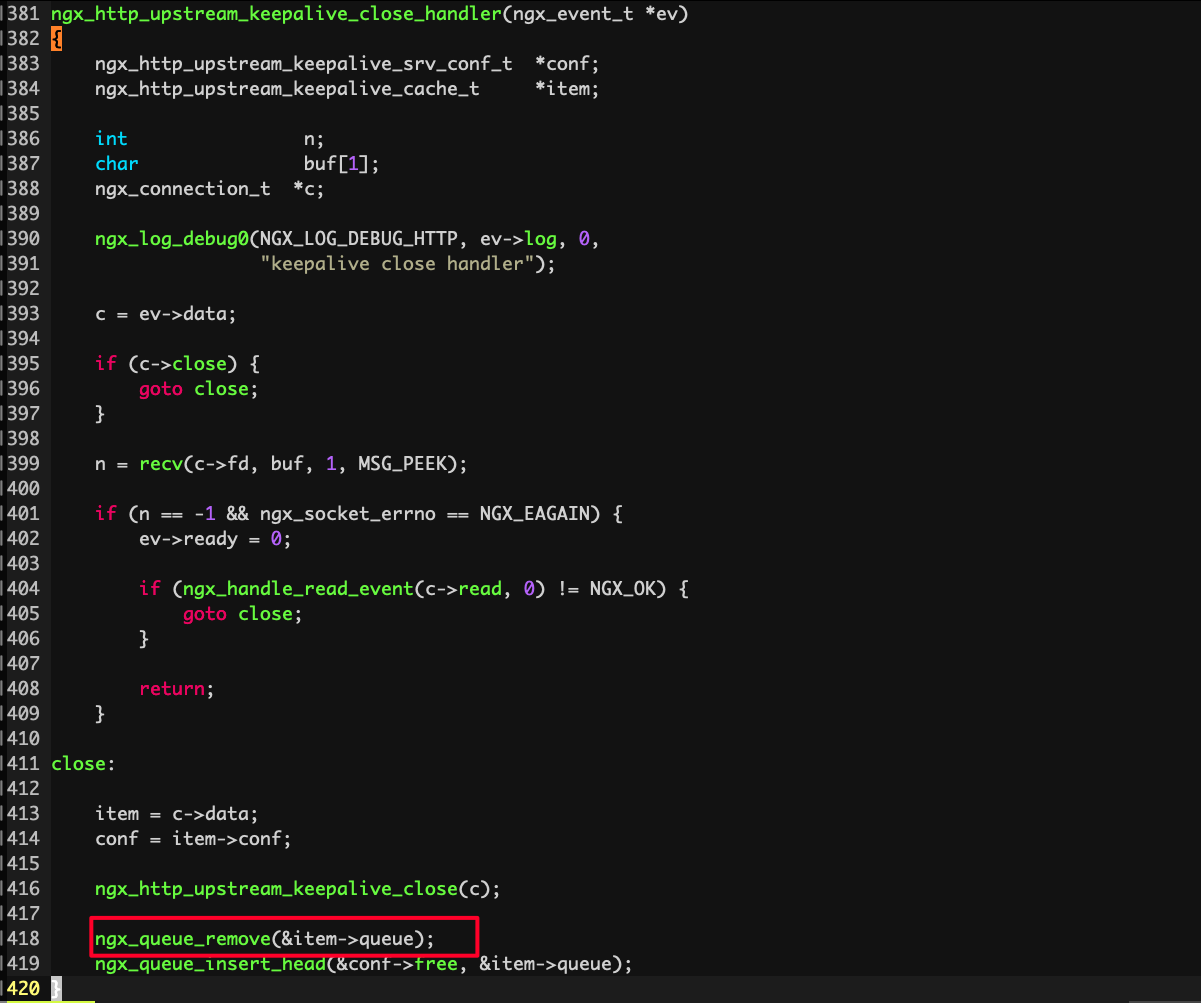
相关代码
看起来是在某个经常挂了之后重新拉起新的worker进程时,在做挂掉进程善后工作的时候,需要删除的节点(item)已经被删了。
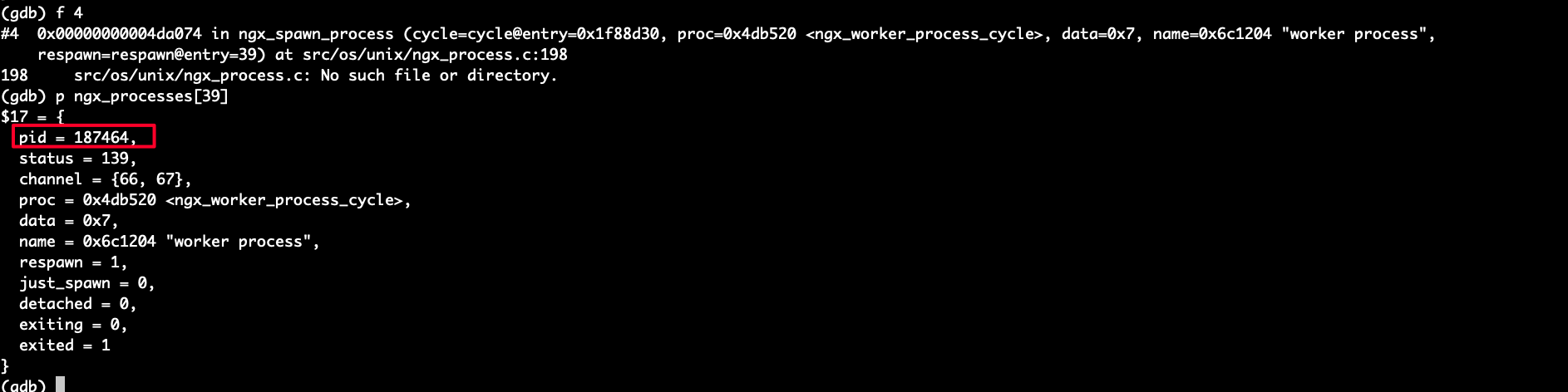
按照这个思路,我查看了对一下ngx_processes数组,通过上面的堆栈信息,我们发现 ngx_spawn_process 这个函数在进程出 core时,传入的respawn=39,对应经常信息如上图。但是这个 pid 对应的 worker 在 一个多小时前(相对于我查看的这个 core)就 core 了。
有几点疑问:
1. 出 core 地方 item->queue->next为空,或者是 item 这个节点会被多个进程操作吗?
2. 为会在一个多小时候拉起 core 掉的 worker 进程呢?不应该是里面拉起吗?
3. 为啥拉起一个之前 core 掉的进程,会导致 worker 进程 core 掉,不是应该 master 进程操作吗?
4. 导致 core 的根本原因是啥?
ps 这次出 core 是批量出 core 整个机房的所有实例都 core 了,都是在后端几个关键时间点,很诡异。
看来几天,还是没找到原因,求各位大神指点,这个怎么定位?怎么解。